Why Legacy Approaches to Data Quality Don’t Work
May 17, 2023
Anyone who works with large amounts of data knows there are uncountably many ways for data quality to suffer. For the modern business that depends on its data to make decisions, bad data means bad decisions. Therefore, maintaining data integrity needs to be a top priority.
Data quality monitoring software has been around for decades to help businesses in this pursuit. Think of tools that let subject matter experts test the data by running it through thousands of validation rules, or dashboards and reports that track changes in key performance indicators (KPIs). These approaches might have been sufficient 5 years ago, when a company’s data was more predictable, came from fewer external sources, and was much smaller in volume. But today, legacy techniques simply don’t scale and risk letting quality issues slip by undetected.
In this post, we’ll compare legacy software to a more modern methodology that emphasizes machine learning. We’ll make the case that traditional monitoring strategies aren’t enough on their own; ML is a must-have for a complete data quality platform.

Legacy approaches to data quality monitoring
Rules-based monitoring
Legacy data quality software relies primarily on validation rules; the user specifies invariants the data ought to adhere to, and the software sends alerts when those constraints are violated. For example, consider a dataset cataloging mobile app user data:
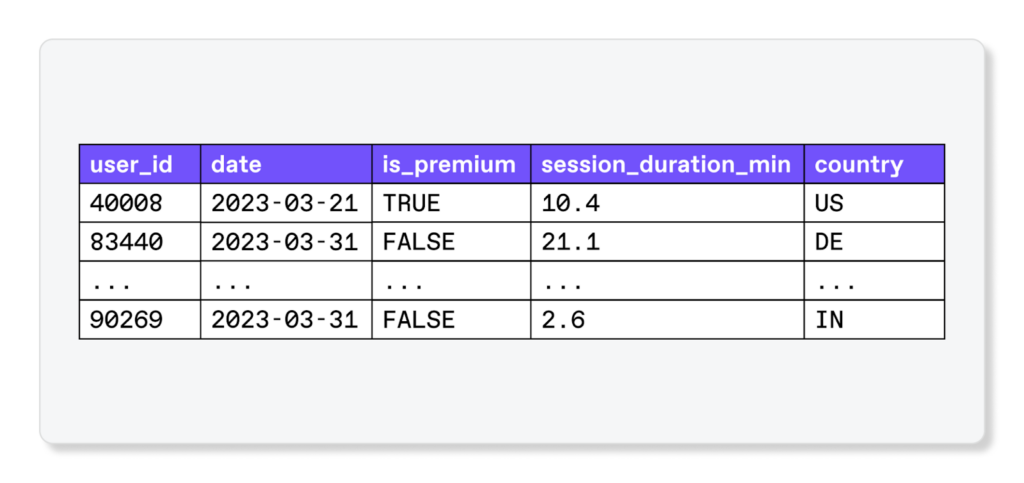
There are all sorts of rules that it could be reasonable to enforce. It is common to ensure that values are of the right data type, such as only booleans being allowed in the is_premium column. Going a step further, values in session_duration_min should likely be non-negative and potentially capped at some upper bound.
Other rules could validate data according to business logic. Maybe the premium version of the app is only available in certain markets, so a rule could check that a row doesn’t show premium usage outside those markets.
Metrics-based monitoring
The second technique legacy data quality tools use is metrics-based monitoring. The end-user designates key metrics to track and the monitoring tool sends alerts if the metric changes unexpectedly. Continuing with the mobile app data example, the business may choose to track average session duration. Should that metric suddenly drop, engineers could investigate to discern whether sessions truly have gotten shorter or if logging or something else has broken.
Both validation rules and metrics monitoring demand user input that anticipates the sorts of data quality issues that might emerge. The amount of setup can be a barrier to fully adopting a monitoring plan, especially when an organization manages many tables. Moreover, predefined rules and metrics can get stale over time and need to be updated as a business grows and its needs change. On their own, legacy data quality approaches take a lot of effort and fail to comprehensively monitor for data issues.
Machine learning can monitor data at scale
In contrast to the aforementioned data quality monitoring methods, unsupervised machine learning needs no prior user specification. Algorithms take in large amounts of data (often, the more data the better), and identify patterns as well as aberrations from these patterns.
Consider the earlier mobile app example. Suppose an erroneous API update started logging the country code for the United States as USA instead of US. All of a sudden, US sessions would go missing from the table and new USA sessions would appear. Since it’s unlikely such a specific issue would have a corresponding validation rule or metric to trigger an alert, downstream dashboards and calculations that depend on US data could silently break. With machine learning, however, it becomes possible to detect this anomaly and notify the data team to explore further.
A comparison of data quality monitoring methodologies
The monitoring approaches we’ve discussed—validation rules, metrics, and unsupervised machine learning—are each suited differently to various aspects of data quality. Sometimes, the simple solution is appropriate: For example, it’s straightforward enough to configure validation rules requiring data to conform to business logic and avoid duplicates.
To excel in more complex scenarios, however, a data quality monitoring platform will need to go beyond legacy techniques and employ a combination of methodologies. What follows are just a few such examples.
Scenario 1: Verifying data accuracy
More manual techniques, particularly validation rules, are a good fit for preserving data accuracy. With rules, it’s easy to check that data fits real-world criteria and isn’t describing impossible circumstances.
Still, manually specifying rules for every potential inaccuracy is infeasible. For a sense of scale, consider a large enterprise with tens of thousands of columns in need of data quality monitoring. It would literally take millions of hours to write accuracy rules for each column.
This is where unsupervised machine learning is a virtual necessity, in that it can flag anomalous data points. ML algorithms highlight columns that may have been accurate to begin with but changed because of some kind of quality issue. With this kind of automation, it becomes tractable to monitor over a hundred thousand columns at once.
Scenario 2: Checking for missing records or incomplete data
All three monitoring techniques can ensure data completeness—whether a dataset contains all the rows it should and whether individual rows have the right fields. With rules, it’s possible to specify an expected number of records and alert if the number of records is below a threshold. Similarly, the total amount of data can be tracked as a metric, and a corresponding time series model can look for anomalies.
The problem with these legacy techniques, though, is that they don’t offer deeper insight. It’s one thing to know that data is incomplete; it’s even more actionable to know in what way the data is incomplete. Machine learning can pick up subsets of the data that typically have a certain number of records and alert when that composition is off. This type of root cause detection is hard to achieve with rules and coarse-grained metrics monitoring alone.
Scenario 3: Ensuring that a dataset is internally consistent
Unsupervised machine learning really shines with respect to consistency, which is whether data values agree with each other and do not create contradictions. Say a table contains sales data including profits, revenues, and costs. For the data to be consistent, the profits column should exactly match the difference between revenues and costs.
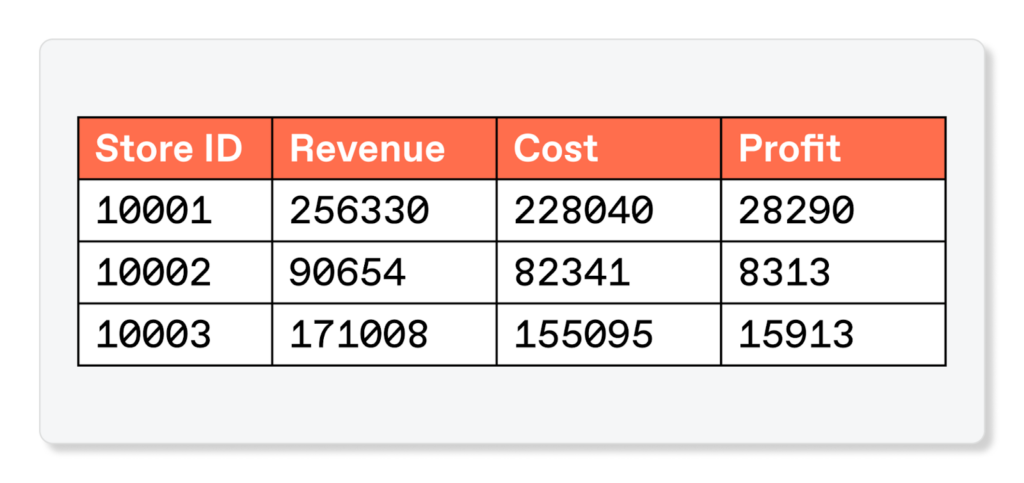
Writing a single validation rule to compare two columns might be practical, but scale quickly becomes an issue when a table contains hundreds of columns that relate to each other in non-obvious ways. For a table with 100 columns, there are 4950 comparisons to be made between any given pair of columns. That number only grows larger when trying to compare groups of three columns or more.
Machine learning enables pairwise and even more complex monitoring of columns. It’s possible to automatically identify abnormalities not just in individual columns but how columns relate to each other. These relationships can be fixed, such as the previous example of profits exactly matching the difference between costs and revenue, or they can be correlations that track whether two columns tend to move together.
Machine learning is at the heart of data quality monitoring with Anomalo
No single technique can comprehensively solve the data quality monitoring problem. Because data quality is multifaceted, it takes a well-rounded platform to monitor it. And with how common large datasets are in today’s world, data quality techniques need to be ready to detect and address issues at a scale that demands automation.
Anomalo takes a modern approach centered on unsupervised machine learning while continuing to offer validation rules and metrics monitoring for businesses to specify key parameters to track. In this way, Anomalo is able to enforce attributes such as data uniqueness validity, while layering on more sophisticated analyses in scenarios too complex for legacy methods. To learn more, reach out for a demo of Anomalo today.
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Get Started
Meet with our expert team and learn how Anomalo can help you achieve high data quality with less effort.