Ensuring Data Integrity in Cloud Migrations with Anomalo
August 29, 2024

In the dynamic realm of data analytics, the ability to accurately migrate and reconcile data across a multitude of platforms is not just a luxury—it’s a necessity. As enterprises continue to shift from legacy databases to sophisticated cloud-based data warehouses, the integrity of data migration has never been more crucial. The success of analytical workflows and jobs heavily depends on the accuracy and reliability of data migration processes. Unfortunately, discrepancies often arise due to issues such as incompatible data types, dropped rows, or differences in metric calculations between two data warehouses. Anomalo offers a solution to the daunting task of data reconciliation without the prohibitive costs and computational demands typically associated with such endeavors.
The Crux of Data Migration Challenges
The transition from legacy databases to cloud data warehouses presents a unique set of challenges. One of the most significant challenges is ensuring that the migration process does not compromise the quality or integrity of the data. This is crucial because any discrepancies introduced during migration can have far-reaching implications for business analytics and decision-making processes. Traditional methods of data reconciliation, such as exhaustive row-by-row comparisons or broad metadata analyses, are either prohibitively expensive or lack the granularity needed to catch critical discrepancies.
Traditional Methods: A Brief Overview
- Row-by-row comparison: A detailed comparison of every row and column across databases is comprehensive. but it requires substantial computational resources and time, making it impractical for large datasets.
- Metadata comparison: Comparing metadata, such as column names and row counts, provides a high-level overview of the data’s integrity. However, it often misses finer details that could significantly affect data analyses, such as minor but critical discrepancies in data values. It also doesn’t show where the discrepancies are, leading to a “needle in a haystack” problem.
Data Reconciliation with Anomalo
Anomalo’s innovative approach to data reconciliation combines efficiency with precision, effectively addressing the limitations of traditional methods. This solution is grounded in two primary strategies that together ensure a thorough, yet resource-efficient reconciliation process.
Anomalo has recently expanded its capabilities to include support for a wide array of legacy databases, including SAP HANA, MySQL, Oracle, Teradata, Db2, and SQL Server. This development is significant, because it acknowledges the diverse data ecosystems within which modern enterprises operate, allowing a broader spectrum of enterprises to benefit from Anomalo’s advanced data reconciliation tools and facilitating smoother transitions to cloud platforms.

Strategy 1: Leveraging Unsupervised Machine Learning for Data Distribution Analysis
The first pillar of Anomalo’s approach involves the application of unsupervised machine learning algorithms to analyze the distribution of data between the source and target databases. These algorithms eases detection without the need for human labeled and data allowing for monitoring at scale. By only using a random sample of rows from each table, this technique allows Anomalo to identify statistically significant discrepancies without the need for a detailed scan of every data row. By focusing on the distribution of data, this strategy efficiently highlights areas where the data’s integrity may be compromised due to the migration process. This method is not only less resource-intensive but also highly effective in catching systemic discrepancies that could undermine data analyses.
Let’s take a closer look on how to do this. In Anomalo, navigate to either the source or target table of interest. Within the Data Quality section, find the Validation Rules and select the “Compare two aggregate SQL queries” check.

Consider a scenario where we’re comparing a table of bank transactions originally stored in SAP HANA and migrated to Databricks. Our objective is to identify any changes across the entire table by sampling 10,000 rows out of a table exceeding 1 million rows. Unfortunately, this migration was compromised by several data quality issues, which are common in faulty migrations. Specifically:
- All values in the
balancecolumn were increased by 100x compared to the original SAP HANA table. - Rows with
NULLvalues in theoperationscolumn were dropped.
We label our SQL queries for retrieving rows from the SAP HANA table as sap hanaoriginal and from the Databricks table (post-faulty migration) as databricks bad migration.
The unsupervised machine learning algorithm in Anomalo detects these statistically significant differences, leading to a failure in the check. The initial visualization clearly indicates “extreme differences” between the two tables. A notable discrepancy is the differing row counts, immediately signaling potential issues with the migration process.


Digging deeper, Anomalo provides a comprehensive analysis of all affected columns. Although the algorithm identifies anomalies across seven columns, it highlights the most critical ones. The egregious anomalies include a 100-fold increase in the mean balance and the operations column’s NULL values dropping from 17.3% to 0.0%. Additionally, the significant reduction in rows affects the distribution of values in the ‘type’ column, presenting as the third anomaly.

This example underscores Anomalo’s capability to swiftly identify and alert users to major issues in data migration, such as those introduced in this hypothetical migration from SAP HANA to Databricks. Moreover, the process’s efficiency is evident in its minimal demand on database resources, querying only 10,000 random rows rather than undertaking a full dump of the table. This not only saves computational resources but also ensures database administrators can maintain operational efficiency while securing data integrity.
Strategy 2: Targeted Metric Comparison with Tolerance Levels
Anomalo’s second strategy addresses the need for precision in data reconciliation by enabling targeted comparisons of specific metrics critical to an enterprise’s operations. This approach goes beyond general statistical analyses to pinpoint discrepancies in vital data points, ensuring that businesses can trust the integrity of their most important metrics post-migration. Furthermore, the introduction of a tolerance feature in this comparison process is a game-changer. It allows businesses to differentiate between meaningful discrepancies and minor differences that do not impact the overall integrity of the data. This feature is especially valuable when dealing with variations in computational behavior across different databases, where slight numerical differences may arise from technical nuances rather than actual data discrepancies.
Let’s dive into the application of this strategy within Anomalo and the insights users can gain from it. Start by navigating to the Validation Rules section under Data Quality for either your source or target table. Here, you should add the “Compare two SQL query result distributions” check.

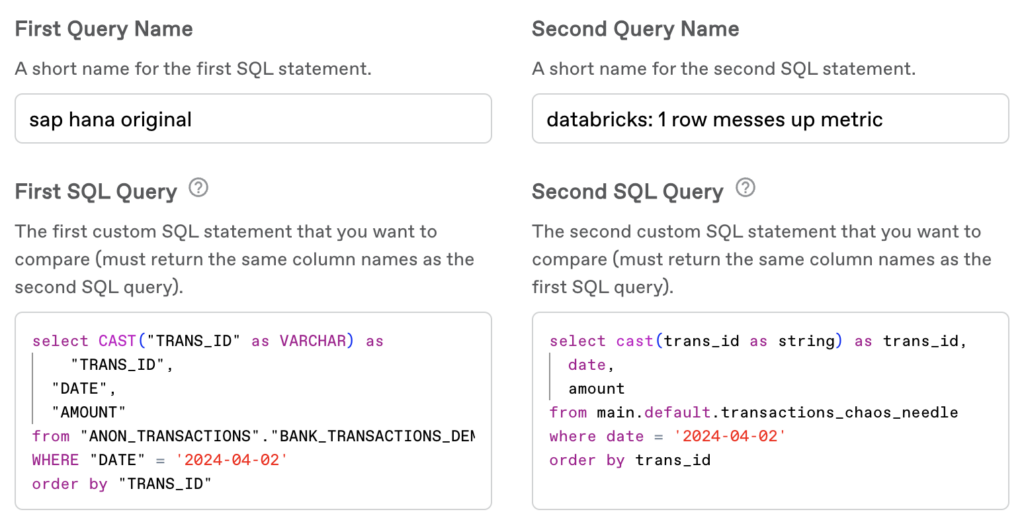
In our illustrative scenario, we revisit the bank transactions table analyzed in Strategy 1. However, we now focus on a specific discrepancy in the Databricks table, where only one value in the amount column differs from the original SAP HANA table—a classic “needle in the haystack” problem. This singular discrepancy is significant enough to influence the average amount metric we aim to compare between the two tables. The SQL queries used to extract the daily average amount from both the SAP HANA table (sap hana original) and the Databricks table (databricks:1 row messes up metric) are designed to highlight this discrepancy, albeit allowing for a minor difference in aggregates to accommodate the slight computational variations between databases.

Upon execution, the check indicates a failure due to unmatched SQL results. Initial visualizations reveal that, for 99.95% of the days (over a period of 2,191 days), the average amounts are consistent across tables, with an exception on one specific day.

This pinpoint precision allows us to identify the exact day of discrepancy—April 2, 2024—effectively finding our “needle.”


Further visual analysis and a subsequent drill-down into the data for April 2, 2024, show a substantial metric deviation: the average jumps from 178.86 to 400.97. This anomaly triggers a deeper investigation into the amount values for that day.
To isolate the issue, another check is performed to scrutinize all amount values for April 2, 2024. This focused examination reveals the mismatching row, where the amount was erroneously recorded as 999,999 instead of the correct 288.9 from the original SAP HANA table.

Identifying the precise location and nature of the discrepancy enables targeted corrective actions, whether through manual adjustments or modifications to the migration logic. This exemplifies Anomalo’s capability not only to detect minute yet significant data migration errors but also to guide users towards resolving these issues efficiently, thereby safeguarding the accuracy of critical business metrics. This strategic application underscores the power of focused metric comparison in maintaining data integrity across migrations, ensuring that businesses can rely on their data for informed decision-making.
Why Anomalo’s Approach Marks a Paradigm Shift
Anomalo’s innovative solution to data reconciliation represents a significant departure from traditional methods, offering a blend of efficiency and precision that directly addresses the core challenges of data migration. Here are several reasons why Anomalo’s approach is revolutionary:
- Cost and Computational Efficiency: By eschewing the exhaustive row-by-row comparisons, Anomalo drastically reduces the computational resources and time required for data reconciliation. This efficiency makes it feasible for enterprises to ensure the integrity of their data without incurring prohibitive costs.
- Precision and Relevance: The dual strategies of statistical data distribution analysis and targeted metric comparison ensure that Anomalo’s reconciliation process is both precise and relevant. Enterprises can focus their efforts on resolving discrepancies that have a tangible impact on their operations, enhancing the overall quality of their data analyses.
- Inclusivity and Accessibility: With the expanded support for a wide range of legacy databases, Anomalo’s solution is accessible to a broader array of enterprises. This inclusivity ensures that more organizations can leverage Anomalo’s advanced reconciliation tools, facilitating smoother data migrations across the industry.
Conclusion
In the complex and ever-evolving landscape of data analytics, Anomalo stands out as a trailblazer, offering a sophisticated yet practical solution to the challenges of data migration. Its innovative approach, marked by computational efficiency and precision, provides enterprises with the tools they need to ensure the integrity of their data. By enabling smoother transitions from legacy databases to modern cloud platforms, Anomalo not only facilitates enhanced analytical capabilities but also empowers businesses to make more informed decisions based on reliable data. In a world where data integrity is critical to success, Anomalo’s pioneering solution is not just an improvement; it’s a revolution in data reconciliation.
Categories
- Product Updates
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Get Started
Meet with our expert team and learn how Anomalo can help you achieve high data quality with less effort.