Anomalo Expands Data Monitoring for BigQuery & Dataplex
August 31, 2023
In supply chain management, it’s long been standard to implement quality control for physical warehouses. Now with software being integral to so many businesses, companies are starting to realize that quality control is just as important for their data warehouses. All it takes is a handful of issues to compromise trust in your entire data operation.
At Anomalo, we’ve been focused on solving the data quality problem for enterprises so they can automatically monitor their data with no incremental effort. We’ve also made it a point to partner with data warehouse providers like Google BigQuery so mutual customers have a seamless experience managing and governing their data.
We’re happy to share that Anomalo’s BigQuery integration includes additional table observability and data lineage features. With table observability, customers can monitor their warehouses more frequently and at a lower computational cost. Then, our new lineage features enable customers to take action on their alerts by pinpointing where issues are coming from and what they’re affecting.
Table observability and data lineage for BigQuery
Anomalo’s table observability features give BigQuery users the big picture of their data warehouse’s health. Because the observability checks are lightweight and inexpensive, it’s easy to run them often to have an up-to-date snapshot of your data pipelines, even at enterprise scale.
Table observability gives hourly insights into key questions including:
- Does the table exist?
- Have any columns been dropped?
- Has the table been recently updated?
- Is the row count as expected?
Asking these questions is the first line of defense against data quality issues. You’ll know sooner rather than later that something is broken, which can make the difference between promptly containing the situation versus having to deal with a major outage that propagates through all your systems.
When Anomalo flags a data concern, our new lineage features can help you trace the issue through your data systems. Anomalo hooks into Google’s Dataplex lineage graph to determine both the upstream causes and and the downstream consequences of a data quality issue. This way, you can contextualize an alert’s severity and respond accordingly.
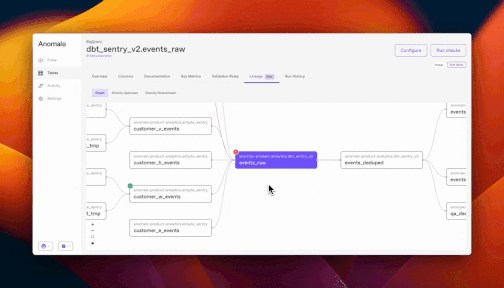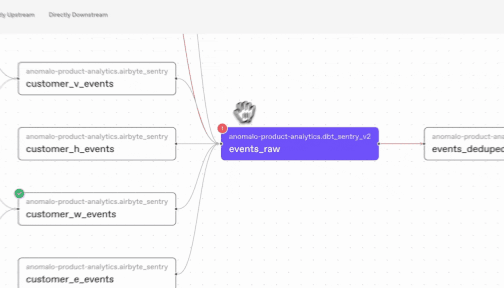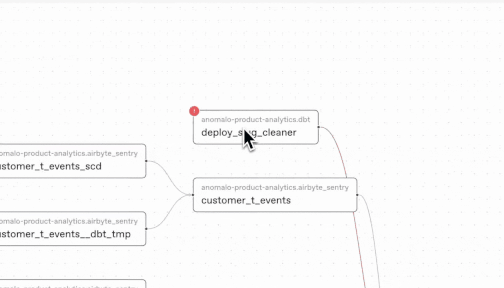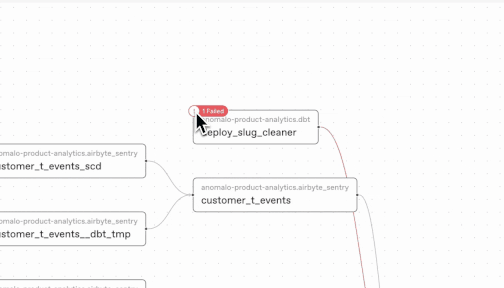
Comprehensive data quality for BigQuery
Anomalo’s expanded capabilities for BigQuery complement our existing suite of deep data quality monitoring tools to make Anomalo the most fully featured solution on the market. We expect customers will use table observability to cover all of their BigQuery tables and apply what we call deep data quality to their most important ones.
Observability is important in quickly evaluating your data pipelines to make sure that everything is operational. With deep data quality, Anomalo goes a step further by examining the actual contents of your data so that not only do you know that your data arrived on schedule and in the right quantity, but that the values are not distorted in any way.
For example, deep data quality addresses questions including:
- Is my data correct and consistent, based on the recent past and subject matter experts’ expectations of what the data should look like?
- Are there significant changes in my metrics?
- Why is my data unexpectedly changing? What is causing these issues?
- Are my ML inputs drifting? Why?
And because there are so many ways data could be awry, it’s not feasible to manually write validation rules for every possible problem. Anomalo has pioneered a novel approach to data quality monitoring grounded in machine learning so that you can automatically scan your enterprise-scale data for discrepancies in ways you could not have predicted.
Now that BigQuery customers have access to data observability, lineage, and ML-powered monitoring all through Anomalo, it’s easier than ever to level up along the data science hierarchy of needs:
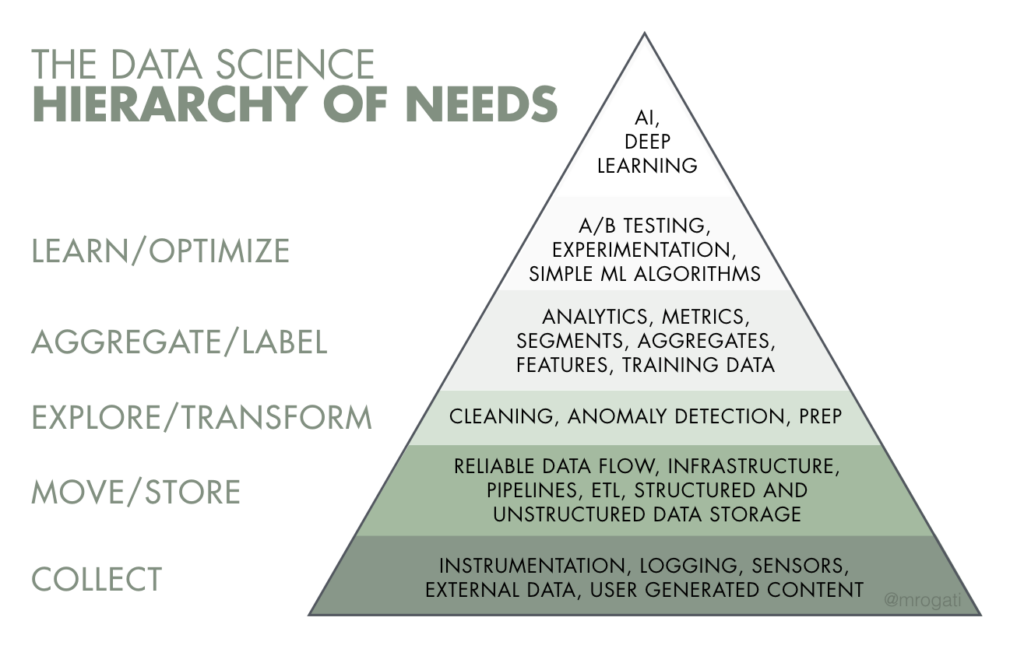
Perhaps the best part is that Anomalo requires no code to get started thanks to its intuitive graphical UI. Your organization’s more technical users can also interact with Anomalo through its API or CLI, giving plenty of options for everybody to have a stake in data quality.
How to start using BigQuery and Anomalo together
It takes less than five minutes to start using Anomalo with BigQuery. From Anomalo, simply enter a few details about your BigQuery account and with one-click, you’re ready to go.
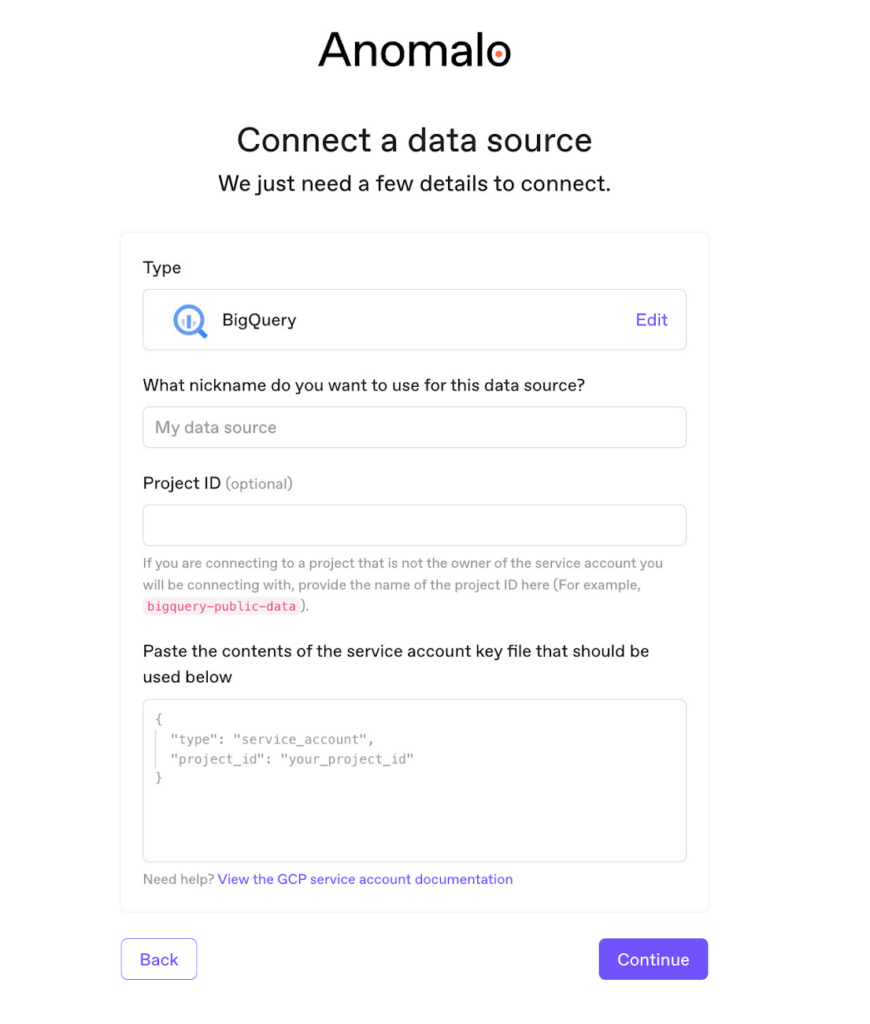
Data observability checks will automatically run with no further set up. To enable data lineage, make sure to grant the appropriate GCP permissions to Anomalo and also enable lineage for the GCP projects of your choice.
That’s it! You can sit back and trust that Anomalo is doing the heavy lifting of regularly checking on your data quality.
For more information, please don’t hesitate to contact your CS representative. And if you’re new to Anomalo, we’re always happy to chat, so request a demo today.
Categories
- Integrations
- Product Updates
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Ready to Trust Your Data? Let’s Get Started
Meet with our team to see how Anomalo transforms data quality from a challenge into a competitive edge.