Data Ingestion vs Data Integration: Understanding Key Differences
October 17, 2024
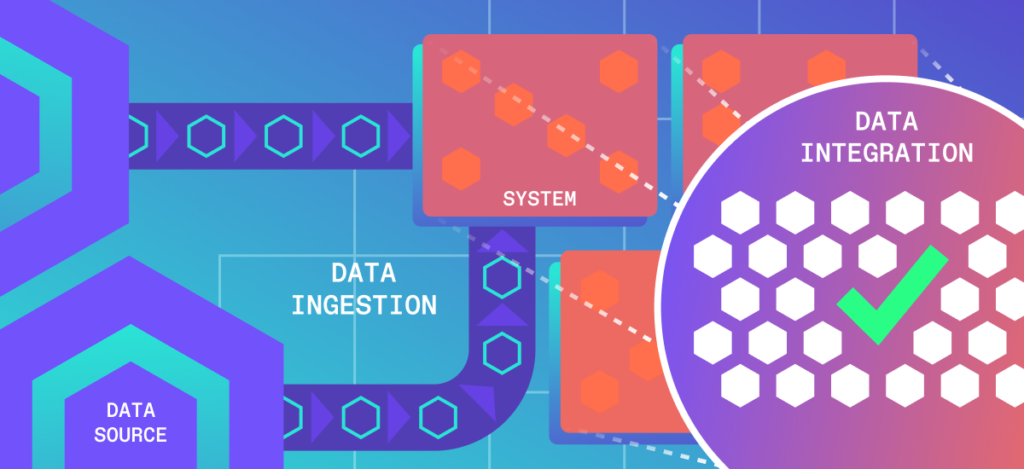
One of the advantages that modern companies have is the ability to comprehend and utilize data on a much larger scale, tracking each step of the customer lifecycle. As a result, the ability to collect, process, and analyze vast amounts of information is crucial for maintaining a competitive edge. At the heart of their data ecosystems lie two critical processes: data ingestion and data integration. While often confused or used interchangeably, these distinct steps in the data pipeline play unique and essential roles in transforming raw data into actionable insights.
The data ingestion process involves collecting and importing data from various sources into a system for further processing. On the other hand, data integration involves merging and organizing data from multiple systems into one cohesive view for analysis and decision-making. Understanding the nuances between these two processes is vital for businesses aiming to maintain data quality and effectively leverage insights derived from their data assets.
As organizations grapple with the challenges of managing an increasing volume of data, they must maintain data quality throughout the ingestion and integration processes. This is where innovative solutions like Anomalo come into play. By leveraging artificial intelligence, Anomalo offers a cutting-edge approach to resolving data issues related to both ingestion and integration, ensuring that businesses can trust the integrity of their data at every stage of the pipeline.
Data Ingestion: The Foundation of Data Pipelines
Data ingestion serves as the critical first step in any data pipeline, acting as the foundation upon which all subsequent data processing and analysis are built. It involves the process of collecting and importing data from various sources into a system where it can be further processed, analyzed, and stored. This initial stage is crucial as it determines the quality and quantity of data available for downstream operations.
There are several methods of data ingestion, each suited to different types of data sources and business requirements:
1. Batch ingestion: This method involves collecting and loading data at scheduled intervals. It’s particularly useful for processing large volumes of data that don’t require real-time updates. For example, a retail company might use batch ingestion to update its sales database nightly.
2. Streaming ingestion: In contrast to batch processing, streaming ingestion allows for data to be ingested in real-time, enabling up-to-the-second updates. This method is crucial for applications that require immediate data processing, such as fraud detection systems or real-time analytics dashboards.
3. APIs (Application Programming Interfaces): APIs provide a more flexible and complex approach to data ingestion. They allow different systems to communicate and exchange data efficiently on an as-needed basis, making them ideal for scenarios where data needs to be pulled from various external sources or services.
While data ingestion is fundamental to building robust data pipelines, it comes with its own set of challenges. Handling large volumes of data can strain system resources and require careful planning to ensure scalability. Dealing with disparate data formats from various sources can add additional process with robust data validation. Moreover, ensuring the reliability and security of the ingestion process is paramount, especially when dealing with sensitive or mission-critical data.
To address these challenges and ensure smooth ingestion, organizations should adhere to several best practices:
- Implement thorough data validation at the source to catch and correct errors early in the pipeline.
- Design ingestion processes with scalability in mind, allowing for easy accommodation of growing data volumes.
- Establish comprehensive monitoring systems to quickly identify and resolve any errors or bottlenecks in the ingestion process.
- Prioritize data security by implementing encryption, access controls, and audit trails throughout the ingestion workflow.
By laying a solid foundation with effective data ingestion practices, organizations set the stage for successful data integration and analysis, ultimately driving more informed decision-making and business growth.
Data Integration: Combining Data from Multiple Sources
Data integration processes involve merging and organizing data from multiple systems into one cohesive view for analysis and decision-making. This crucial step in the data pipeline transforms raw, disparate data into a unified, valuable resource that can drive business intelligence and strategic planning.
Here are the most common strategies for data integration:
- ETL (Extract, Transform, Load): This traditional approach involves data extraction from various sources, transforming it into a desired format or structure, and then loading it into the target system, such as a data warehouse. ETL is particularly useful when dealing with complex transformations or when the target system has specific data format requirements.
- ELT (Extract, Load, Transform): A more modern approach, ELT reverses the order of operations. Data is extracted from source systems and loaded into the target system in its raw form. Transformations occur later, typically within a data warehouse or data lake. This method is often more flexible and can take advantage of the processing power of modern data storage systems.
Data integration faces its own set of challenges. Some of these include ensuring data consistency across different sources and formats, managing and reconciling data from legacy systems with modern data structures, and maintaining data quality and accuracy throughout the integration process. On top of these, real-time integration requirements for time-sensitive applications can add additional overhead.
To overcome these challenges and optimize the data integration process, organizations should consider the following best practices:
- Setting up robust data mapping to ensure accurate translation between different data models
- Automating repetitive tasks to reduce errors and improve efficiency
- Implementing data governance frameworks to maintain data quality and consistency
- Using metadata management to improve data discoverability and understanding
- Regularly auditing and updating integration processes to ensure they meet evolving business needs
By effectively integrating data from multiple sources, businesses can gain a comprehensive view of their operations, customers, and market trends, enabling more informed decision-making and strategic planning.
Key Differences Between Data Ingestion and Data Integration
While both data ingestion and data integration are essential components of the data pipeline, they serve distinct purposes and occur at different stages. Understanding these differences is crucial for designing effective data management strategies.
| Aspect | Data Ingestion | Data Integration |
| Process | Focuses on collecting and importing raw data from various sources | Combines and refines data from different sources into a unified view |
| Stage in Data Pipeline | Occurs at the beginning of the pipeline | Typically happens after data has been ingested |
| Goal | Ensures data is available for processing | Ensures data is useful for analysis and decision-making |
| Scope | Deals with individual data sources | Works across multiple data sources |
| Output | Raw or minimally processed data | Structured, harmonized data ready for analysis |
While distinct, data ingestion and integration complement each other:
Data ingestion feeds raw data into systems, providing the necessary input for subsequent processing. Data integration takes this ingested data and transforms it into a cohesive, analyzable format. Together, they ensure that data is not only available but also meaningful and actionable for business insights.
Both processes are essential for maintaining high-quality data and enabling data-driven decision-making. Effective ingestion ensures that all relevant data is captured, while successful integration makes this data useful by providing a unified, consistent view across the organization.
The Role of Anomalo in Ensuring Data Quality
With the inherent complexity in managing a large volume of data, organizations are looking for solutions to make this process smoother and simpler. This is where Anomalo’s AI-driven platform plays a crucial role, helping businesses automatically monitor, detect, and resolve data issues in real-time across both the ingestion and integration phases of the data pipeline.
Anomalo’s advanced AI algorithms can identify a wide range of data quality issues:
For data ingestion, Anomalo can detect incomplete or incorrect data from various sources, ensuring that only high-quality data enters the system. For example, it might flag unusual patterns in streaming data that could indicate a sensor malfunction or a data transmission error.
For data integration, Anomalo can identify inconsistencies when merging data from different sources, such as mismatched fields, conflicting information, or unexpected changes in data distributions. This helps maintain data integrity throughout the integration process.
Here are some real-world examples of how this has helped businesses:
- A real estate company used Anomalo to detect and alert on sudden changes in many of their tables, allowing them to quickly identify and resolve issues.
- A payments company employed Anomalo to monitor data quality in real-time as they integrated data from a wide variety of sources and searched for anomalies.
By providing these AI-driven insights, Anomalo helps businesses achieve better accuracy by catching and correcting errors early in the data pipeline. In addition, there is an improvement in timeliness through real-time monitoring and alerts and enhanced consistency by ensuring data coherence across various sources and systems.
The result is clean, accurate data that leads to better decision-making, more reliable business intelligence, and improved operational efficiency. With Anomalo, organizations can trust their data, focusing on deriving insights rather than questioning data quality.
Conclusion
Understanding the key differences between data ingestion and data integration is crucial for building effective data pipelines and maintaining high-quality data assets. Data ingestion forms the foundation by collecting and importing raw data from various sources, while data integration transforms this data into a cohesive, analyzable format.
Both processes come with their own set of challenges and best practices. Without proper implementation of both, businesses risk compromising their data quality, leading to unreliable insights and flawed decision-making.
Innovative solutions like Anomalo play a vital role in this data quality landscape. By leveraging AI to automatically monitor, detect, and resolve data issues in real-time, Anomalo ensures that businesses can trust their data throughout the entire pipeline – from ingestion to integration and beyond.
To experience firsthand how Anomalo can revolutionize your data quality management and provide you with trustworthy, actionable insights, we encourage you to try a demo of the product. Discover how AI-driven data quality assurance can transform your business decision-making and operational efficiency.
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Get Started
Meet with our expert team and learn how Anomalo can help you achieve high data quality with less effort.