Enabling AI at Scale: Lakehouse Data Quality & Orchestration
March 15, 2024

McKinsey’s latest research estimates that generative AI could add the equivalent of $2.6 trillion to $4.4 trillion in annual economic benefits. However, for large businesses, the recipe for AI success is anything but straightforward. Complicated, fractured data pipelines, as well as scale challenges, compound the difficulties of implementing generative AI.
During a recent expert roundtable with Pradeep Anandapu, Senior Staff Partner Solutions Architect at Databricks, and Zach Wright, Solution Engineer at Anomalo, we discussed the latest trends in data quality and orchestration — and why both are essential for AI success. This roundtable also covered:
- What recent innovations in data quality & orchestration are improving AI scalability?
- Where are organizations finding data quality & data orchestration synergies within their AI initiatives?
- Which best practices increase your odds of success?
- What are the best high-return starting points?
In this blog post, we’ve summarized the highlights. You can watch the full roundtable below:
Becoming a data-forward enterprise
“[Being] a data-forward enterprise means making sure AI and data are in every part of your business,” explained Anandapu. According to Gartner, over 20% of organizations have made substantive progress on generative AI use cases, and another 70% are planning to invest in the technology. For most organizations, the question isn’t whether to implement generative AI within the business but how to scale their data infrastructure and practices for AI.
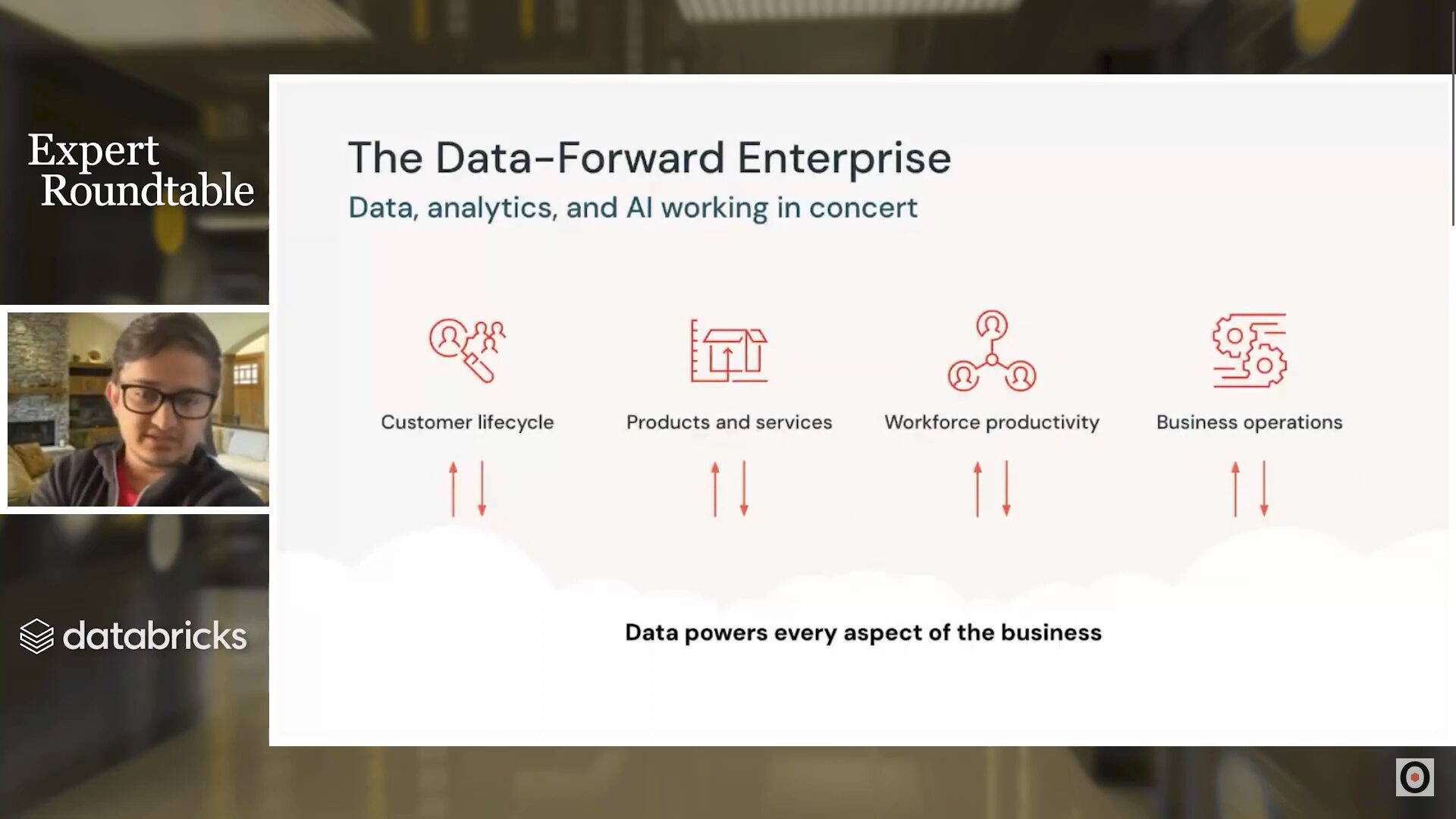
Extracting value from data has always required that the data itself be reliable. Generative AI is no different—in fact, it may require organizations to raise their data quality standards due to large language models widening access to previously inaccessible data. As Wright put it:
LLMs are going to expand the scope of data questions in the lakehouse. Where there’s historically been a bottleneck on technical skill set, there’s now going to be data that is unlocked that users can access because it’s going to be much more accessible through LLM models.
Ensuring reliable data is the job of data orchestration and data quality tools, such as Databricks and Anomalo. Data orchestration is the process of combining disparate sources of data that your organization holds into one queryable location, enabling business intelligence and AI use cases. Data orchestration goes hand-in-hand with data quality—you need to be able to trust your data before using it for business-critical tasks.
Anomalo and Databricks integrate seamlessly. Using the two tools together can unlock powerful automated workflows, for example, as Wright explains:
If a very severe data quality issue is found, we want to halt the process so the data doesn’t go over to the gold layer. This could save end users from getting faulty data that can strongly impact the business.
Data quality monitoring at LLM scale
Data quality monitoring has always presented organizations with scale challenges. Large quantities of columns across tables of different sizes and formats, paired with complex business requirements, mean that it’s unaffordable to implement comprehensive data quality checks manually. Generative AI will make more of your data accessible, increasing the necessary bar for data quality coverage.
For example, Discover, an Anomalo customer, has around 125,000 business data columns. Pre-Anomalo, they found that implementing data quality checks would take around 40 hours of a data engineer’s time across the lifetime of a single column. Assuming 100 data engineers and 2,000 productive hours per engineer per year, it would take 25 years to achieve 100% business data quality.
What’s more, LLMs will make data accessible to more people, meaning that data quality requirements will only get more demanding with time. Meeting this data quality scale challenge, therefore, is both necessary and urgent. Traditional approaches can help here:
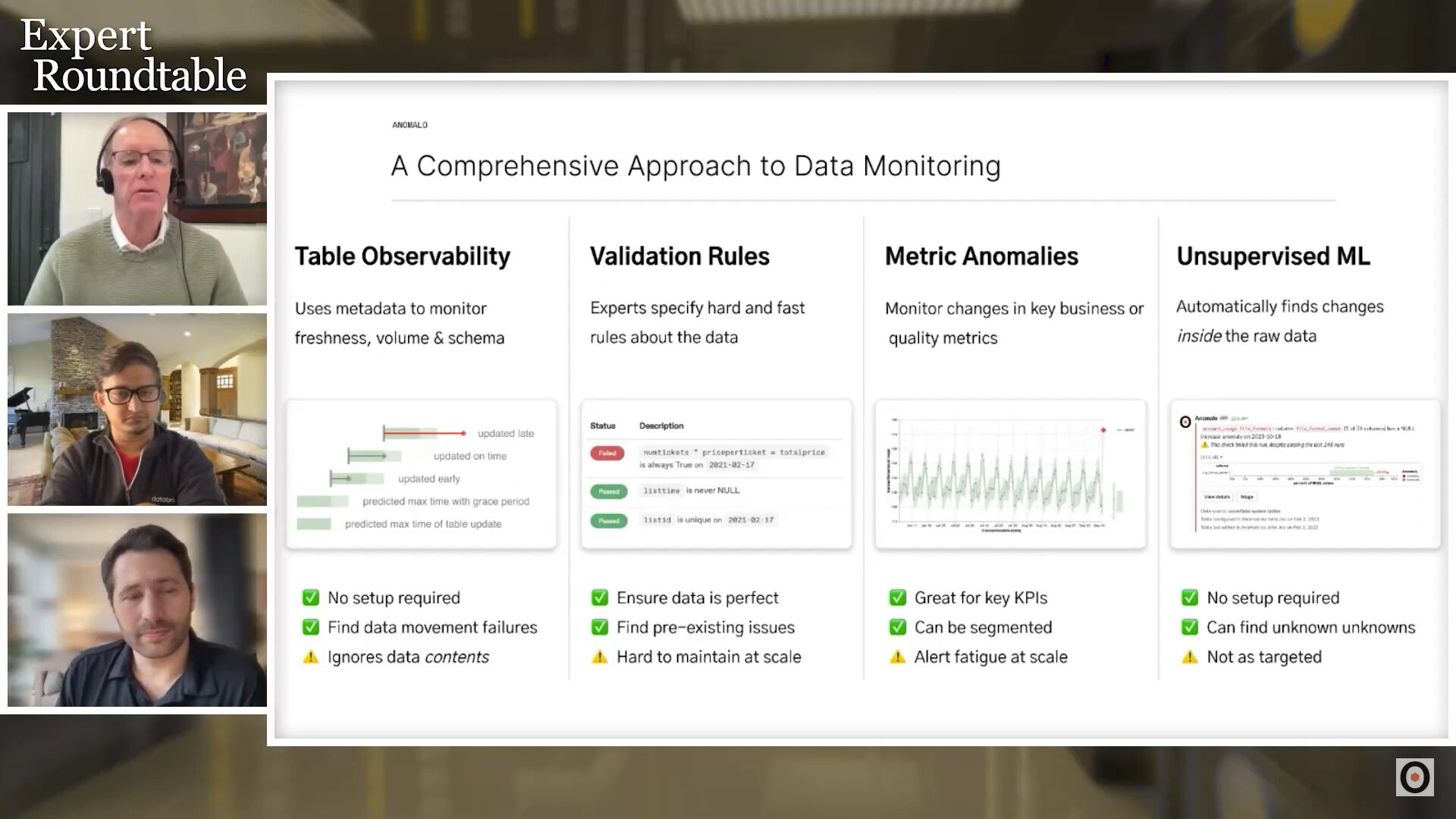
- Table observability, including completeness and schema drift checks, is relatively cheap to implement and can be applied across all tables.
- Metric anomaly detection can help catch errors at a high level. For example, if the average value of a transaction suddenly drops, it could highlight errors in the data pipeline.
These approaches by themselves aren’t sufficient to achieve data quality, however. Every check you implement, especially high-level checks like the above, has a false positive rate that can contribute to alert fatigue. Alert fatigue doesn’t just impact team morale, it also leads to ignoring alerts because they are too noisy—which means that real problems can slip by.
One modern approach to data quality monitoring is unsupervised learning. This is a machine-learning technique that can automatically detect deviations from the regular patterns in your data. Unsupervised learning lets you enable deep monitoring on all tables without configuration. Because it adapts to the data, it can help you reduce alert fatigue and discover unknown-unknowns that you wouldn’t have predicted when writing validation rules.
High-return starting points
Improving data orchestration and quality is a critical first step to introducing generative AI in your organization. What’s more, it can help you make better business decisions, improve customer outcomes, and save engineering time in debugging issues. Our panelists suggested a few high-return places to start during the roundtable.
Adopting the lakehouse architecture
The traditional data architecture setup has been to store structured data in a data warehouse and unstructured data in a data lake. Data warehouses are more typically used for business intelligence use cases, while data lakes see more machine learning and AI usage.
Having multiple data silos presents a number of challenges. For one, moving data between silos requires a lot of effort and often leads to inconsistencies. Secondly, maintenance, security, and governance become exponentially more challenging as you add more platforms to your data infrastructure. Most importantly, data silos multiply the amount of work required to enable generative AI for your organization.
The data lakehouse solves many of these issues by unifying your data into one place. Anandapu summarizes it as “all the workloads on all of your data unified in one place.”
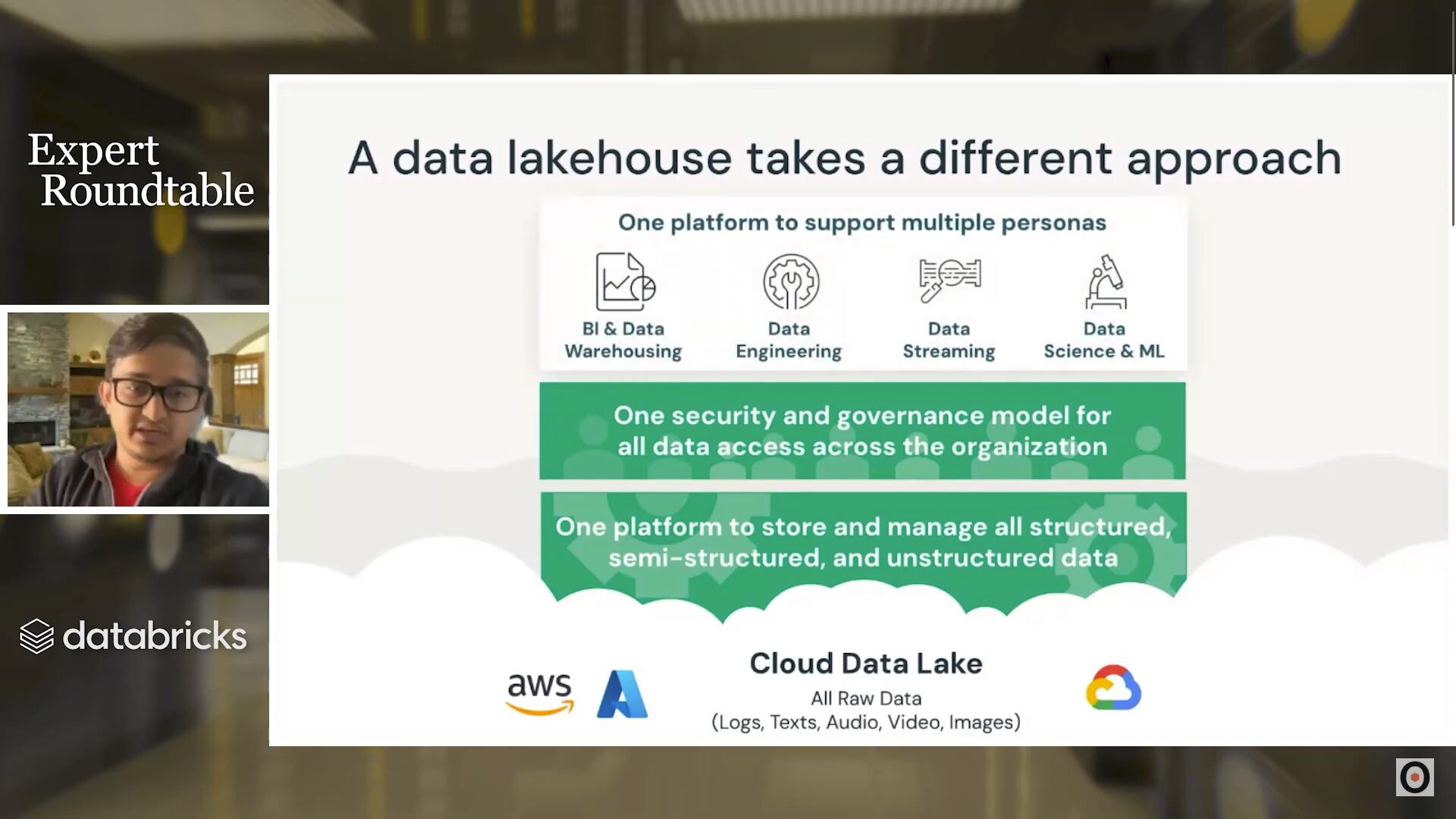
Furthermore, the new Databricks Data Intelligence Platform merges the lakehouse architecture with Generative AI, enhancing the implementation of data science applications across enterprises. This will shift the focus even more towards data quality.
Automated root cause analysis
Data engineers are a limited resource within organizations, and their time is valuable. Wright used to be a data engineer and much of his time was spent performing root cause analysis: “When I was a data engineer, 50% of my time was dedicated to figuring out why data quality issues were happening and where specifically in the data they were occurring.”
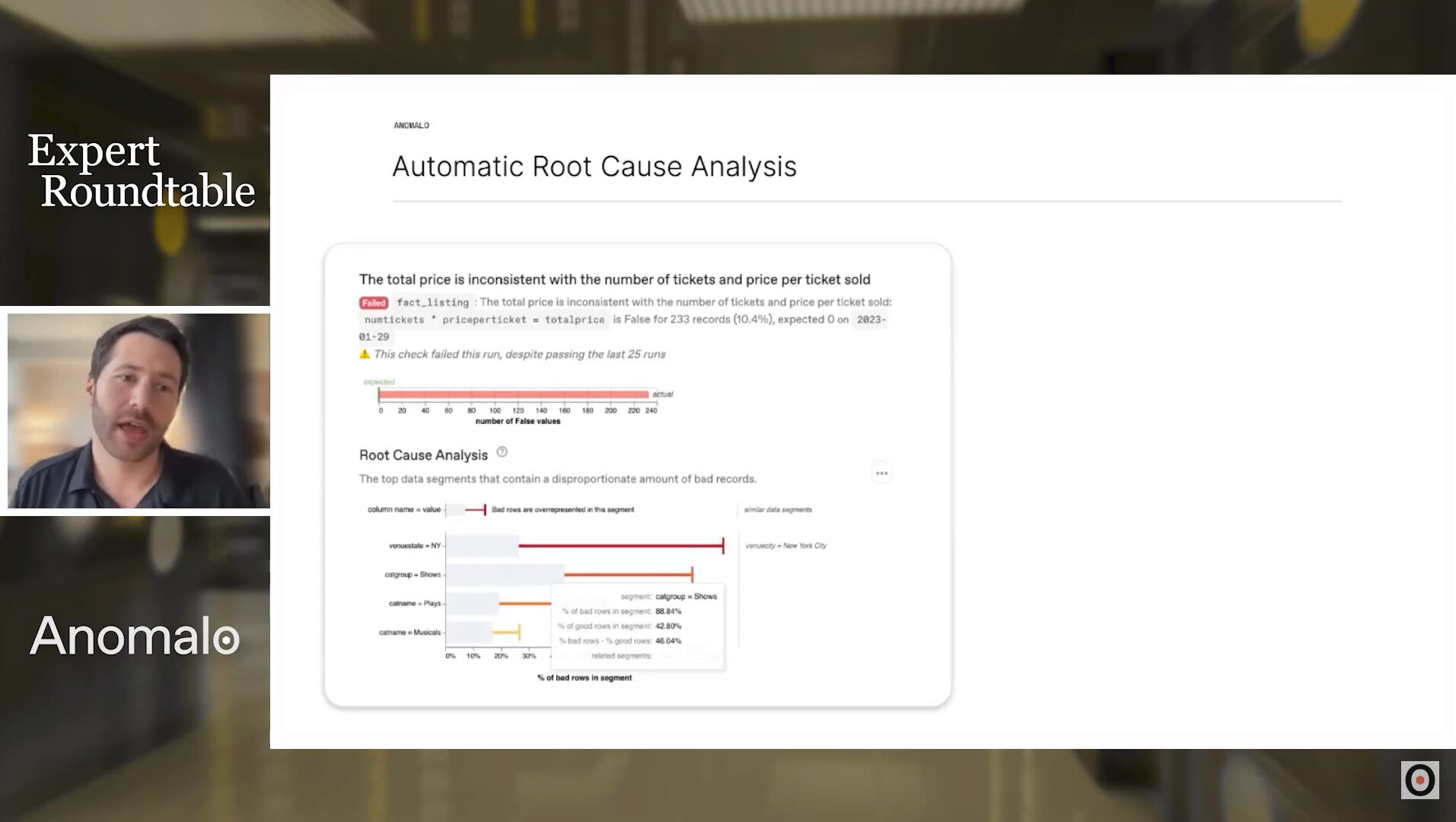
Performing automated root cause analysis with a data quality tool such as Anomalo significantly reduces the burden on data engineers. Anomalo can figure out the likely root cause of a data issue and present it to engineers along with samples and rich visualizations.
Automated root cause analysis frees up data engineers’ time to enable them to focus on business goals, such as enabling generative AI.
Conclusion
Adopting generative AI is something that many organizations are rightly interested in. However, data quality issues remain one of the most significant obstacles to maximizing the value of data and AI. The first step in any adoption plan should be ensuring that the existing data orchestration and quality infrastructure is up to scratch, something Anomalo and Databricks are well-suited to help with.
To learn more about enabling AI at scale, you can watch the full webinar here:
If you’re interested in improving your data quality monitoring, request a demo with Anomalo today.
Related Resources
Learn more by browsing our library of announcements, guides, and technical deep dives on data quality.



Get Started
Meet with our expert team and learn how Anomalo can help you achieve high data quality with less effort.